Framework Architecture
ConsumerBench orchestrates realistic GenAI workloads through a flexible, graph-based execution model.
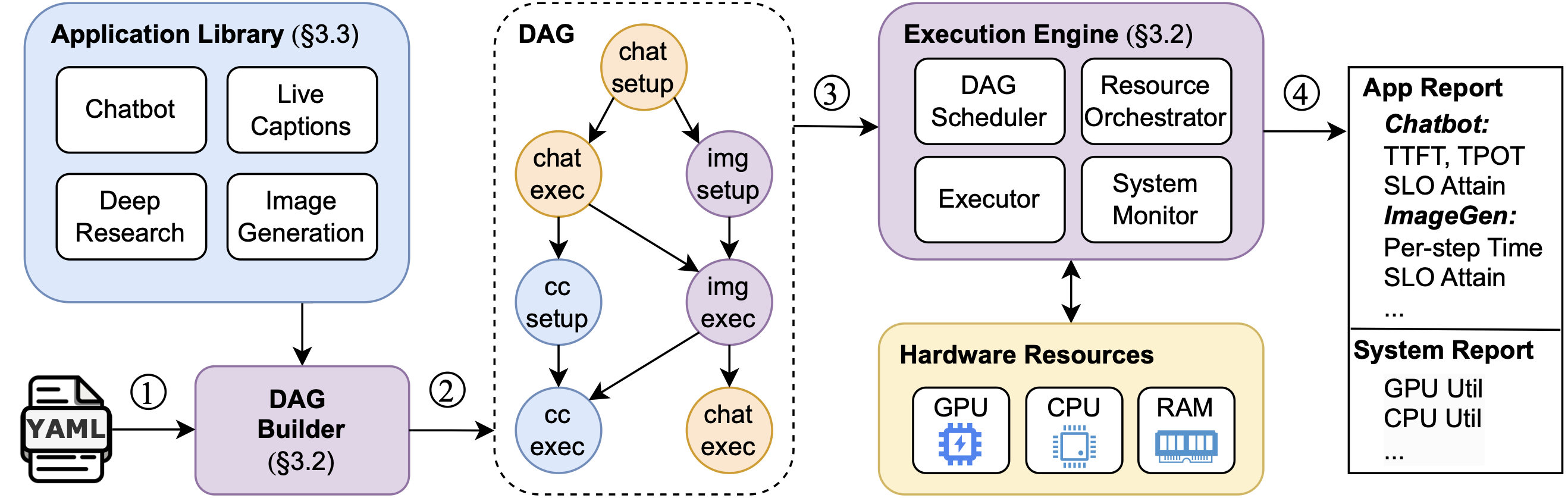
ConsumerBench architecture: from YAML configuration to DAG execution with comprehensive monitoring and reporting
Simple YAML Configuration
(a) Task Definition
1 Analysis (DeepResearch): 2 model: Llama-3.2-3B 3 num_requests: 1 4 device: cpu 5 Creating Cover Art (ImageGen): 6 model: SD-3.5-Medium-Turbo 7 num_requests: 5 8 device: gpu 9 slo: 1s 10 Generating Captions (LiveCaptions): 11 model: Whisper-Large-V3-Turbo 12 num_requests: 1 13 device: gpu 14 ...
(b) Workflow Definition
1 analysis_1: 2 uses: Analysis 3 cover_art: 4 uses: Creating Cover Art 5 depend_on: ["analysis_1"] 6 analysis_2: 7 uses: Analysis 8 depend_on: ["analysis_1"] 9 generate_captions: 10 uses: Generating Captions 11 depend_on: ["cover_art", 12 "analysis_2"] 13 ...
Example YAML configuration showing (a) task definition with models and SLOs, and (b) workflow definition with dependencies
Key Features
- Multi-application workflows: Define tasks and dependencies using simple YAML
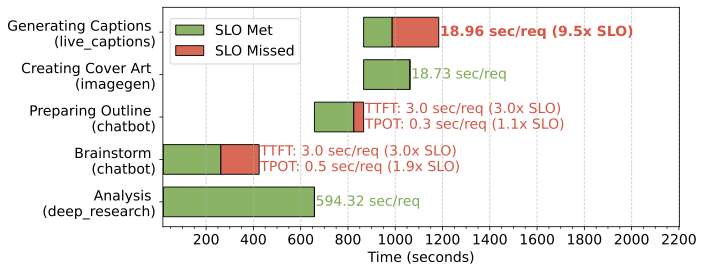
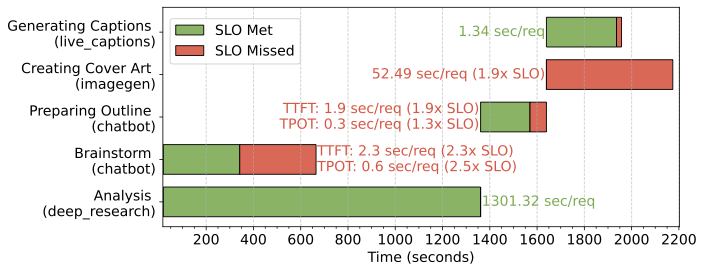
- SLO tracking: Measure per-app latency and SLO attainment
- System-level monitoring: GPU/CPU utilization, memory bandwidth, power via NVIDIA DCGM and Intel PCM
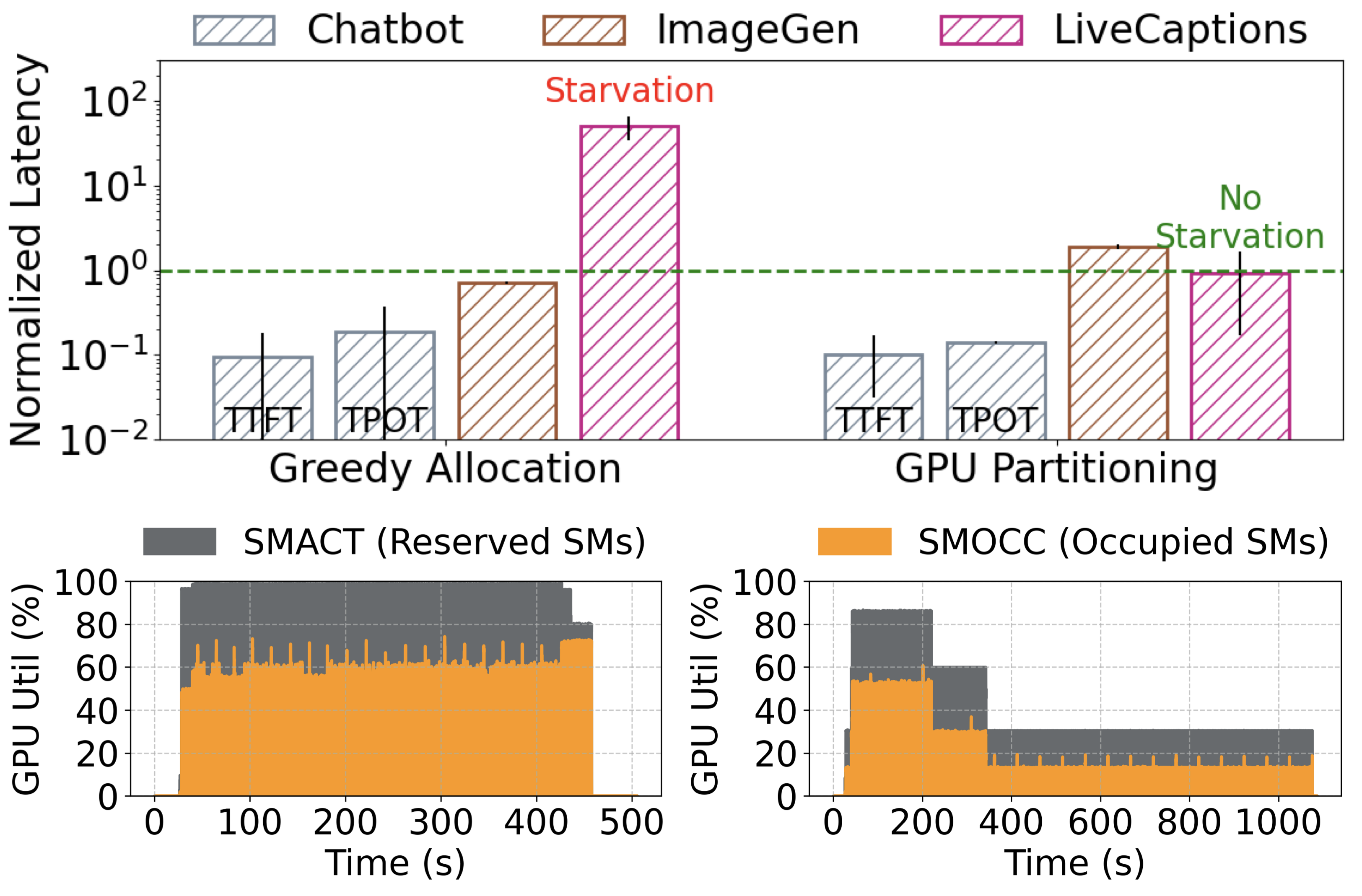
- Flexible orchestration: Greedy allocation, static partitioning, or shared inference servers
- Extensibility: Plug in custom apps via
setup(),execute(),cleanup()interface
Supported Applications
| Application | Modality | Model |
|---|---|---|
| Chatbot | text → text | Llama-3.2-3B |
| DeepResearch | agent | Llama-3.2-3B |
| ImageGen | text → image | SD-3.5-Turbo |
| LiveCaptions | audio → text | Whisper-v3-Turbo |
These applications span interactive and background workloads, reflecting modern consumer AI diversity.